
Basta usare ChatGPT e altri per un po’ per rendersi conto delle capacità di questi modelli e dei loro limiti, a cominciare dalla loro fabbricazione. Per molti leader del settore, questi problemi iniziali verrebbero risolti aumentando le dimensioni dei modelli e i volumi di dati su cui vengono addestrati. Meglio ancora, questa scala sempre crescente consentirebbe prima o poi di raggiungere il Santo Graal dell’intelligenza artificiale generale.
Questa logica o questa legge empirica, che giustifica trimestre dopo trimestre gli investimenti nelle capacità di calcolo degli hyperscaler, convince sempre meno persone e anche questi seguaci più ardenti cominciano a dubitare. Pertanto GPT-5, il prossimo “modello di frontiera” di OpenAI annunciato per la fine dell’anno, non mostrerebbe gli stessi progressi dei suoi predecessori, riferisce The Information. I miglioramenti prestazionali attesi non ci sarebbero e, nonostante l’aumento dei parametri (17.000 miliardi secondo alcune fonti), i modelli continuano a produrre allucinazioni, errori di ragionamento e altre risposte incongrue. Ex assistente di Sam Altman presso OpenAI e ora capo della sua stessa azienda, Ilya Sutskever ha detto a Reuters che i risultati dell’aumento della pre-formazione si sono stabilizzati.
“Ogni nuova versione di un modello importante sembra fornire solo guadagni marginali rispetto alle versioni precedenti, indicando che i fornitori vedono rendimenti decrescenti. Ad esempio, mentre GPT-4 mostra miglioramenti rispetto a GPT-3.5 nel ragionamento e nei compiti specializzati, i guadagni non sono proporzionali al massiccio aumento delle risorse di calcolo richieste”, afferma Erik Schwartz, direttore dell’intelligenza artificiale presso Tricon Infotech presso The Stack media.
Il fatto che OpenAI e altri stiano affrontando e riconoscendo i limiti dell’approccio incentrato sulle dimensioni delizia gli esperti che già ne dubitavano, come Gary Marcus e più recentemente Yann Lecun. “Le valutazioni elevate di aziende come OpenAI e Microsoft si basano in gran parte sull’idea che gli LLM, man mano che si svilupperanno, diventeranno intelligenze generali artificiali. Come ho sempre detto, è solo una fantasia. Non esiste una soluzione di principio alle allucinazioni nei sistemi che si basano sulle statistiche linguistiche senza una rappresentazione esplicita dei fatti e senza strumenti espliciti per ragionare su tali fatti”, scrive Gary Marcus sul suo blog.
Grafico creato da Gary Marcus sull’evoluzione delle prestazioni del modello (misurate sul benchmark MMLU).
Miglioramenti dell’inferenza e usi limitati
Naturalmente questa non è la fine dei principali modelli linguistici. I modelli attuali hanno dimostrato le loro sorprendenti capacità conversazionali e di generazione di contenuti e la loro adozione continuerà laddove i loro limiti non rappresentano un problema: il chatbot per le raccomandazioni turistiche sì, quello utilizzato per la diagnosi medica automatizzata no. D’altra parte, per avvicinarsi ad un’IA più affidabile e più generale, sarà senza dubbio necessario sviluppare nuove tecniche complementari, come l’IA neuro-simbolica di Marcus o l’IA pianificatrice di Lecun.
Inoltre, altre tecniche applicate non all’addestramento ma all’inferenza, cioè al momento dell’interazione con modelli esistenti, consentono di ridurre i problemi di confabulazione – senza però eliminarli. L’uso di informazioni controllate per alimentare le risposte (RAG), la spiegazione vincolata del ragionamento in background (catena di pensiero, utilizzata in o1 di OpenAI) sono tra i metodi già sfruttati per migliorare i risultati dei modelli esistenti. Senza dimenticare il concatenamento di agenti specializzati e lo sviluppo di grandi modelli specializzati addestrati su corpora di contenuto controllato.
Lo spostamento del carico computazionale dal pre-training all’inferenza preannuncia uno spostamento nella distribuzione della capacità, con meno mega-dacenter che concentrano tutte le GPU e più potenza distribuita nei quattro angoli del globo vicino agli utenti, analizza Sonya Huang, partner di Sequoia Capital . Da diversi mesi Microsoft rassicura i suoi azionisti promettendo che le costose infrastrutture di formazione potranno essere riutilizzate per l’inferenza.
I piccoli modelli competono con i loro anziani
Se le prestazioni dei modelli grandi tendono a convergere e a migliorare solo marginalmente, i modelli piccoli procedono ad alta velocità. E risultano essere più economici e meno dispendiosi in termini energetici, sia per l’addestramento che per l’inferenza. Kai-Fu Lee ha recentemente condiviso un modello ultra efficiente sviluppato dalla sua azienda 01.ai, (6a nel benchmark LMSYS, secondo l’azienda), addestrato per soli 3 milioni di dollari e che mostra un costo di inferenza di 10 centesimi per un milione di token. Per fare un confronto, la formazione di GPT-4 sarebbe costata quasi 100 milioni di dollari (rispetto al miliardo di GPT-5) e il milione di token viene fatturato tra i 10 e i 60 dollari.
Se 01.ai ha lavorato principalmente sull’ottimizzazione delle inferenze, altri metodi sono in voga per ridurre la dimensione dei modelli. Una tecnica è la rimozione mirata di alcuni strati da un modello di grandi dimensioni con un impatto trascurabile sulle prestazioni. Con questo processo, Nvidia ha sviluppato modelli che raggiungono prestazioni paragonabili a Mistral 7B e Llama-3 8B, utilizzando fino a 40 volte meno token di addestramento. , secondo il rapporto sullo stato dell’intelligenza artificiale.
Un’altra tecnica, la distillazione, prevede l’utilizzo di modelli di grandi dimensioni per produrre dati raffinati che vengono poi utilizzati per addestrare modelli più piccoli ed efficienti. Il modello Gemma 2 9B di Google, ad esempio, è stato distillato con il suo fratello maggiore Gemma 2 27B.
L’ambizione di eseguire modelli GenAI sugli smartphone stimola questi sviluppi di modelli meno impegnativi. Apple sta quindi sviluppando modelli più piccoli per potenziare il suo servizio Apple Intelligence. Da parte sua, Microsoft ha progettato phi-3.5-mini, un modello con 3,8 miliardi di parametri che rivaleggia con Llama 3.1 8B. Utilizzando la quantizzazione a 4 bit, una tecnica che riduce la precisione con cui vengono rappresentati pesi e attivazioni, il modello utilizza solo 1,8 GB di memoria, consentendo di effettuare inferenze su un dispositivo mobile.
Stesse prestazioni a costi inferiori
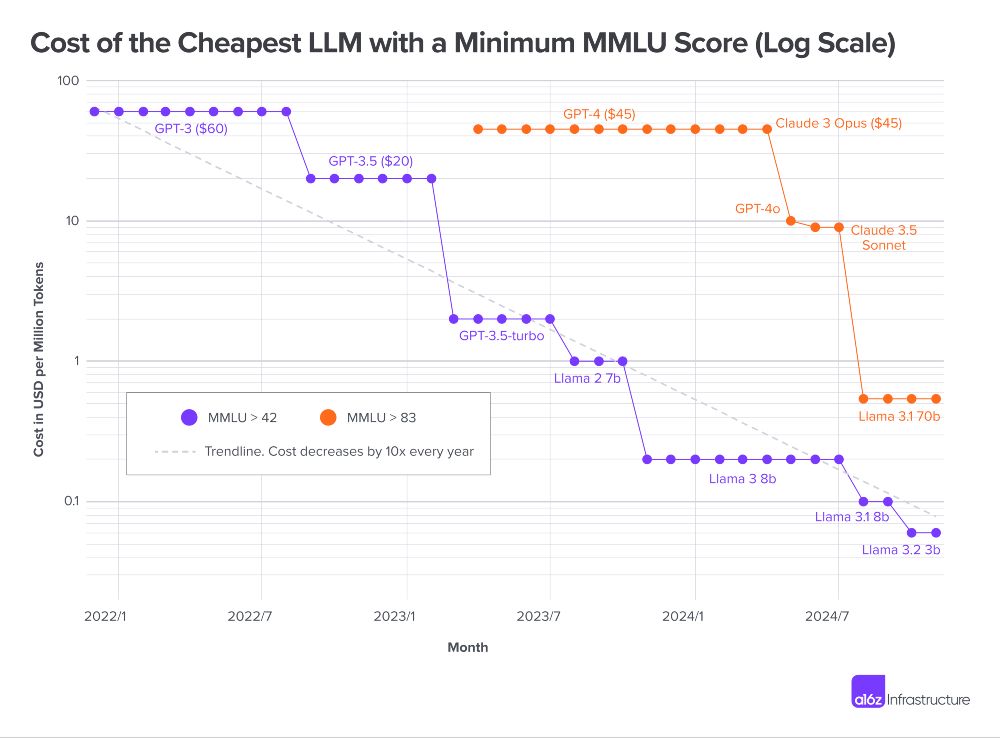
A parità di prestazioni è quindi sempre più possibile utilizzare modelli in scala a minore consumo energetico. È anche possibile farlo a costi inferiori. Secondo l’analisi di Guido Appenzeller, investitore di Andreessen Horowitz, negli ultimi due anni i costi di un LLM con una determinata potenza sono diminuiti drasticamente. Così, quando è stato lanciato alla fine del 2021, GPT-3 costava 60 dollari per un milione di token per una prestazione di 42 sul benchmark MMLU (un test consolidato che copre argomenti in una cinquantina di discipline). Oggi è possibile raggiungere lo stesso punteggio con Llama 3.2 3B, venduto a 6 centesimi per milione di token su Together.ai. Il prezzo per gli utenti è stato diviso per 1000 in tre anni.
Il grafico logaritmico di Guido Appenzeller mostra che, come tendenza, il prezzo dei token per una determinata performance (qui 42 e 83 sul benchmark MMLU) è stato diviso per 10 ogni anno (linea tratteggiata).



